


















Россия
Россия
Россия
В статье исследуются возможности применения искусственного интеллекта (ИИ) и семантических технологий для автоматизации обработки строительных данных и интеграции сметных нормативов (ГЭСН) в процессы информационного моделирования зданий (BIM). Авторы предлагают инновационный подход, сочетающий обработку естественного языка (NLP), онтологическое моделирование и машинное обучение для структурирования неформализованных технических заданий и автоматического формирования стоимостных показателей строительных конструкций. Исследование состоит из двух взаимосвязанных этапов, включающих анализ актуальных публикаций в рассматриваемой области и подтверждение выдвинутой гипотезы, сформированной на основе анализа собранных выборок. В результате исследований установлено, что использование NLP-инструментов, таких как spaCy и BERT, позволяет эффективно извлекать ключевые параметры из текстовых технических заданий, обеспечивая переход от свободной формы описания к структурированному представлению информации. Создание онтологий на основе нормативных баз данных (включая ГЭСН) в формате RDF открывает возможность для семантической интеграции проектных решений с нормативной базой, повышая точность и согласованность сметных расчетов. Применение «четких правил» (rule-based) и машинно-обучающихся методов сопоставления строительных конструкций с соответствующими сметными нормами способствует формированию более адаптивной и интеллектуальной системы ценообразования. Таким образом, проведенное исследование отражает потенциал ИИ для снижения трудозатрат на ранних стадиях проектирования и повышения точности сметных расчетов. Перспективы работы связаны с развитием цифровых двойников и сквозной автоматизацией жизненного цикла строительных объектов.
искусственный интеллект, BIM, ГЭСН, NLP, семантические технологии, автоматизация проектирования
Введение
Современная строительная отрасль находится в периоде активной цифровой трансформации, где одной из ключевых технологий стало информационное моделирование зданий и сооружений (Building Information Modeling – BIM – в зарубежных источниках) [1]. Переход на BIM открывает широкие возможности для повышения точности проектных решений, сокращения ошибок проектирования и улучшения взаимодействия между участниками строительного процесса. В контексте сметного обеспечения внедрение BIM позволяет интегрировать количественно-качественные характеристики объектов проектирования в единую цифровую модель, что потенциально способствует автоматизации процессов ценообразования и управления затратами [2].
Однако, несмотря на значительный потенциал, реальное внедрение экономических расчетов в BIM-процессы сталкивается с рядом существенных препятствий. Одним из основных ограничений является сложность интеграции Государственных элементных сметных нормативов (ГЭСН) в автоматизированные рабочие процессы. Согласно исследованиям, проведённым в рамках программы цифровизации строительной отрасли, большинство специалистов не обладают достаточной квалификацией или доступом к специализированным инструментам для корректного применения сметных норм в цифровых моделях [3].
Дополнительные трудности возникают из-за отсутствия унифицированного подхода к использованию классификаторов информации, как при разработке технических заданий на разработку проектно-сметной документации (ТЗ), так и непосредственно при архитектурно-строительном проектировании. Несмотря на то, что структура ТЗ формально регламентирована Минстроем России, содержательная часть часто остаётся неструктурированной и не соответствует требованиям openBIM, COBie и другим стандартам обмена данными[1], что, в свою очередь, делает последующую автоматизированную обработку информации затруднительной.
Современные системы автоматизации демонстрируют хорошие результаты при работе с высоко структурированными данными. Например, если каждому элементу цифровой модели присвоены параметры материала, объема и типа конструкции, программные средства могут подбирать соответствующие расценки из федеральных или локальных сметных нормативов. Однако, такие подходы являются скорее полумерой: информация выгружается из модели, обрабатывается вне её контекста и зачастую требует ручной доработки [4]. Более того, полноценная обратная связь между информационной моделью и сметными системами реализуется лишь на поздних этапах проектирования, когда управление изменениями в информационной модели представляется весьма затруднительным.
На ранних стадиях жизненного цикла проекта сметные расчеты по-прежнему выполняются вручную или полуавтоматически, что неизбежно приводит к значительным ошибкам и снижению достоверности экономических прогнозов. Таким образом, переход на BIM открывает новые горизонты, однако без системного подхода к стандартизации, классификации и интеграции сметной информации потенциал BIM остается недооцененным и недостаточно востребованным [5].
В [6–8] авторами проверена гипотеза о возможности повышения точности прогнозирования сметной стоимости на начальных этапах архитектурно-строительного проектирования за счёт применения технологии информационного моделирования зданий. По результатам исследований было установлено, что процесс автоматизации сопряжён со значительными трудностями, обусловленными необходимостью полуавтоматического структурирования данных на отдельных этапах работы.
Данная публикация развивает предыдущие исследования авторов, фокусируясь на оценке возможностей семантических технологий искусственного интеллекта в анализе и систематизации неструктурированной информации.
Научно-технической гипотезой данного исследования заключается в возможности применения искусственного интеллекта для структурирования и обработки строительных данных в целях формирования параметров технологического ядра и автоматизированного подбора видов строительных конструкций на этапе архитектурно-строительного проектирования. При этом гипотеза исследования базируется на следующих принципах:
- Процесс проектирования и строительства в первую очередь рассматривается как проектирование и создание специализированного микроклимата, обеспечивающего оптимальные условия для функционирования заданной технологии.
- Форма, компоновка и параметры строительных конструкций определяются необходимостью защиты от внешних воздействий и обеспечения оптимальных условий работы заданной технологии.
- Пространственные и инженерные решения подчиняются требованиям сохранения стабильности параметров искусственной среды, необходимым для корректной эксплуатации технологических процессов.
- Строительные конструкции обязаны в полной мере соответствовать нормативным требованиям безопасности, но при этом должны проектироваться без избыточного запаса прочности и материалоемкости. Критерием оптимальности выступает баланс между надежностью защиты технологического ядра и минимальной ресурсоемкостью строительных систем.
- Выбор строительных материалов должен определяться комплексным анализом, основным параметром которого является «экономичность». «Экономичность» строительных решений представляет собой интегральный показатель, учитывающий не только прямую стоимость строительных материалов, но и совокупные затраты на их транспортировку, обработку, монтаж, накладные и пр. расходы.
Материалы и методы
Схема исследования включает два последовательных этапа: на первом этапе проводится системный анализ актуальных научных публикаций и практических решений в рассматриваемой области, что позволяет сформировать теоретико-методологическую базу исследования; на втором — осуществляется экспериментальное подтверждение выдвинутой гипотезы посредством апробации разработанных методов и анализа полученных результатов. Обобщенная схема исследования представлена на рисунке 1.
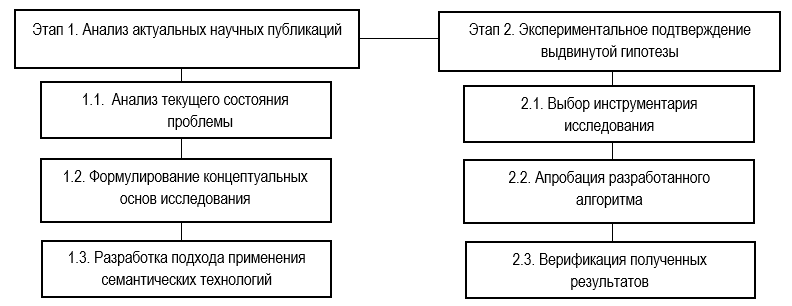
Рис.1. Общая схема исследования
Таким образом, на начальном этапе исследования сформирована репрезентативная выборка научных публикаций из базы данных Scopus за период 2014-2024 годов. Отбор проводился по ключевым словам: «AI in construction design» и «AI in data structuring». Результаты первичного поиска приведены в таблице 1. Далее выполнен системный анализ отобранных публикаций из базы данных Scopus, соответствующих теме исследования.
Таблица 1.
Результаты первичного поиска
|
Ключевое словосочетание |
Количество публикаций |
Тренды по годам |
|---|---|---|
|
AI in construction design |
Более 1 400 |
Рост с 2018 г. (скачок после 2020 г.) |
|
AI in data structuring |
169 |
Стабильный рост с 2016 г. |
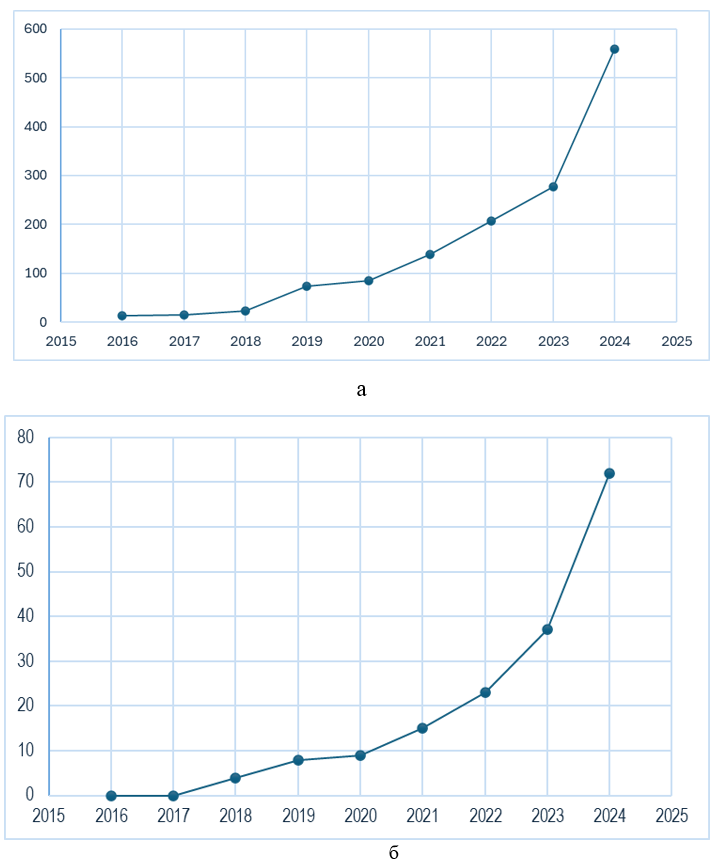
Рис. 2. Динамика роста публикаций, отобранных в Scopus за период с 2014-2024 гг.,
по ключевому словосочетанию: а — AI in construction design, б — AI in data structuring
На втором этапе исследования разработана и апробирована математическая модель, для тестирования которой были использованы данные строительных объектов, отобранных с официального портала госзакупок, охватывающие как стадию проектирования, так и этап практической реализации (строительства).
Результаты исследования
1. Анализ актуальных научных публикаций
1.1. Анализ текущего состояния проблемы
Краткий обзор исследований по применению искусственного интеллекта (ИИ) в проектировании и структурировании информации (2014–2024 гг.). Проведенный анализ позволил выявить основные направления исследований в области применения ИИ для структурирования информации и для проектирования.
Таблица 2.
Результаты анализа публикаций из сформированных выборок
|
Основные задачи и направления |
Применяемые методы и технологии |
Недостатки |
|---|---|---|
|
ИИ для структурирования информации: |
||
|
|
|
|
ИИ для проектирования: |
||
|
|
|
Таким образом, результаты исследований последних лет указывают на ряд существенных ограничений. В первую очередь, необходимо учитывать, что модели ИИ, обученные на исторических данных, могут воспроизводить ошибки, заложенные в исходных наборах данных. Далее, при использовании генеративных моделей (например, на основе архитектур типа LLM) для работы со строительными нормами часто возникают ситуации, когда система предоставляет логично выглядящие, но фактически ошибочные или вымышленные ссылки на нормативные документы. Например, ИИ может сослаться на несуществующий пункт СП или указать неправильный коэффициент пересчёта из ГЭСН, что делает результат недостоверным.
Также отмечаются случаи некорректной интерпретации терминов: модели ИИ могут путать понятия «сметная стоимость» и «рыночная цена», не учитывать региональные коэффициенты или ошибочно применять правила ценообразования с одной стадии проектирования на другую. Подобные неточности могут привести к значительным финансовым и юридическим рискам.
Таким образом, ИИ трансформирует традиционные процессы проектирования и работы с информацией, но требует дальнейшего развития методологической базы и инфраструктуры программного обеспечения для непосредственного внедрения в процессы архитектурно-строительного проектирования.
1.2. Формулирование концептуальных основ исследования
Проведенный анализ актуальных публикаций в рассматриваемой области позволил сформулировать концептуальные основы для данного исследования:
- Применение технологий обработки естественного языка (NLP-инструментов, в т.ч. spaCy, BERT, GPT) для извлечения ключевых параметров из текстовых технических заданий.
- Онтологическое представление нормативной базы (ГЭСН). Преобразование нормативов ГЭСН в формат RDF и построение графовой модели в Neo4j.
- Установление логических связей между проектными параметрами и соответствующими стоимостными нормами.
Концептуальные основы исследования базируются на интеграции современных методов искусственного интеллекта, технологий обработки естественного языка NLP, онтологического моделирования и информационного моделирования зданий с целью автоматизации процесса структурирования неструктурированных данных в области строительного проектирования.
1.3. Разработка подхода применения семантических технологий
Опираясь на проведённое выше исследование разработан следующий подход применения семантических технологий:
- Входные данные: необработанные тексты технических заданий.
- NLP-инструмент: spaCy / BERT — извлечение ключевых параметров.
- Онтология ГЭСН: RDF-граф с нормативами, классами работ и их стоимостью.
- Выходной результат: сметный расчет стоимости строительства.
Данные для анализа были собраны с портала государственных закупок. Исследование было сфокусировано на сравнительно небольших медицинских объектах — фельдшерско-акушерских пунктах (ФАПах), что обусловлено наличием репрезентативной статистики и возможностью мониторинга трансформации информации в процессе исследования.
2. Экспериментальное подтверждение выдвинутой гипотезы
2.1. Выбор инструментария исследования
В качестве инструментария использован готовый фреймворк для обработки документов с помощью LLM с конструктором NLP-пайплайнов — Llama 3, развернутый на локальном компьютере. Выбор указанного фреймворка обусловлен гибкой настройкой параметров работы, в частности управление «температурой» («temperature») обработки результатов и ручной настройкой фильтрации. Например, фильтрация результатов обработки текста по доверенным источникам:
|
trusted_sources = ["СП 118.13330", СП 158.13330"] if not any (source in response. context for source in trusted_sources): raise ValueError ("Результат не подтвержден нормативами") |
На первом этапе отобраны ТЗ на разработку проектно-сметной документации. Отбор проводился с учетом полноты представленных данных и соответствия типовым требованиям к техническим заданиям[2].
Технические задания были представлены в различных форматах, среди которых преобладали PDF и DOCX. Эти форматы можно разделить на две основные категории: машиночитаемые документы (текстовые PDF и редактируемые DOCX) и сканированные копии (изображения текста в PDF). Последние требовали дополнительной обработки с использованием технологий оптического распознавания символов (OCR).
Применение OCR-систем позволило преобразовать сканированные документы в структурированный текст, пригодный для дальнейшего анализа. Для машиночитаемых форматов использовались парсеры (PyPDF2, pdfminer, docx2python), извлекающие текст напрямую без необходимости распознавания. Это обеспечило единообразие данных на этапе предварительной обработки и минимизировало возможные ошибки, допущенные при составлении технических заданий.
Таким образом, на начальном этапе исследования была сформирована унифицированная текстовая база ТЗ, готовая для последующего анализа с помощью NLP-алгоритмов. Это позволило перейти к автоматизированному извлечению ключевых параметров проектирования и сопоставлению данных с нормативными требованиями.
Для извлечения сущностей (NER — Named Entity Recognition) были использованы spaCy (предобученная модель ru_core_news_lg для русского языка) и Fine-tuned BERT (DeepPavlov/rubert-base-cased) для специализированных терминов, пример обработки технического задания представлен в таблице 3.
Таблица 3.
Фрагмент обрабатываемой информации технических заданий на проектирование
|
Тип сущности |
Пример из ТЗ |
Извлеченное значение |
|---|---|---|
|
ПОМЕЩЕНИЕ |
"лаборатория" |
{name: "лаборатория", type: "препараты"} |
|
ПЛОЩАДЬ |
"площадь не менее 12 м²" |
{min: 12, unit: "м²"} |
|
ТЕМПЕРАТУРА |
"температурный режим +18...+22°C" |
{min: 18, max: 22, unit: "°C"} |
|
МАТЕРИАЛ |
"стены из негорючих материалов" |
{material: "негорючий", requirement: "стены"} |
|
НОРМАТИВ |
"согласно СП 118.13330" |
{code: "СП 118.13330"} |
Сопоставление с датасетом строительных норм осуществлялось с применением базы нормативов PostgreSQL с классификаторами. База нормативов формировалась по извлеченным ссылкам из технических заданий и по перечню обязательных стандартов и сводов правил[3].
Пример автоматического поиска в датасете для помещения "лаборатория":
|
… "normative": "СП 158.13330", "default_area": 12, // если в ТЗ нет явного указания "requirements": { "ventilation": "5 воздухообменов/час", "fire_safety": "предел огнестойкости стен REI 45" … |
Пример формирования структурированного технологического ядра:
|
… "name": "лаборатория", "type": "laboratory", "sources": { "from_TZ": { "area": {"min": 10, "unit": "м²"}, "humidity": {"min": 50, "max": 60, "unit": "%"}, "materials": ["негорючие"] … "from_norms": { "normative_code": "СП 158.13330", "default_area": 12, "requirements": { "ventilation": "5 воздухообменов/час", "fire_safety": "REI 45" … "final_parameters": { "area": 12, // выбрано макс. значение из ТЗ и норм "materials": ["негорючие", "устойчивые к кислотам"] // объединение требований … |
Как видно из примера, если в ТЗ указана площадь 10 м², а норматив требует 12 м² система идентифицирует расхождение, результирующее значение принимается по требованиям документам высшего приоритета. В результате по каждому техническому заданию были сформированы технологические ядра объектов. Методика перехода от структурированных данных технологического ядра к строительным плоскостям подробно описана авторами в [6-8].
Семантическая модель, которая связывает строительные плоскости со сметными нормативами, разрабатывалась по «четким правилам» (Rule-Based).
|
… def estimate_cost(plane): if plane["type"] == "стена" and "кирпич" in plane["materials"]: return plane["area_m2"] * 1200 # Цена из ГЭСН 08-02-001 elif plane["type"] == "перекрытие": return plane["area_m2"] * 3500 … |
На рисунке 3 представлена упрощенная схема семантической модели.
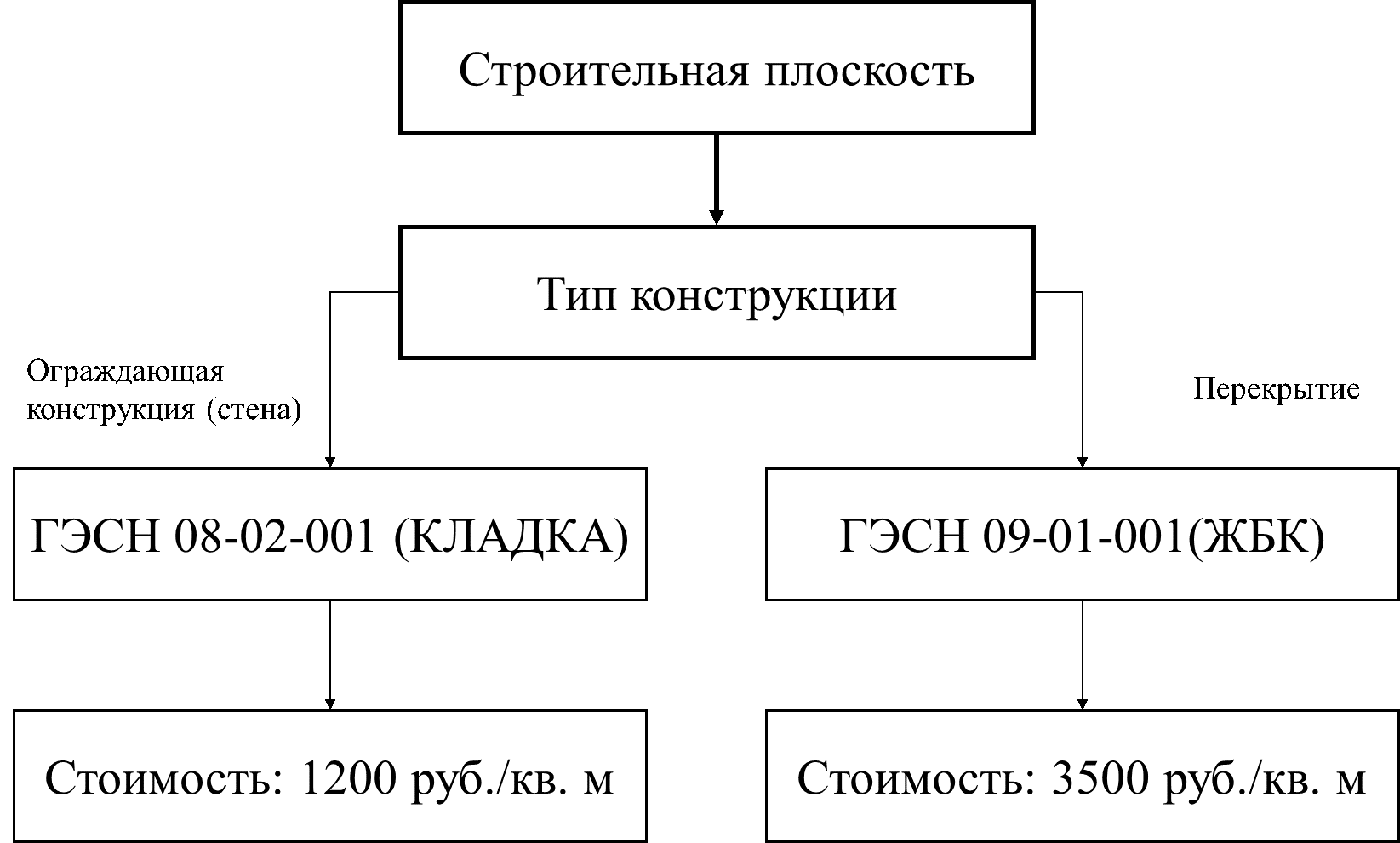
Рис. 3. Упрощенное представление семантической модели присвоения признаков стоимости строительным плоскостям
Для применения интеллектуального подбора таблиц ГЭСН, была осуществлена векторизация базы ГЭСН в числовые вектора, с помощью sentence-transformers (в частности all-MiniLM-L6-v2):
|
… from sentence_transformers import SentenceTransformer model = SentenceTransformer('all-MiniLM-L6-v2') # Строительные плоскости и ГЭСН в одном векторном пространстве plane_desc = "кирпичная стена 50 м²" gesn_desc = "кладка стен кирпичных толщиной в 2 кирпича" similarity = model.similarity(plane_desc, gesn_desc) if similarity > 0.8: apply_gesn_code("08-02-001") … |
2.2. Апробация разработанного алгоритма
Разработанный алгоритм был опробован на 25 объектах ФАПов. Для верификации полученных результатов, была сформирована выборка из пяти объектов (табл.4). Для верификации принимались следующие показатели:
- Площадь помещений технологического ядра по результатам структурирования данных технических заданий.
- Площадь помещений технологического ядра по результатам разработки проектно-сметной документации (данные с сайта государственных закупок).
- Диапазон стоимости (min-max), определенный по семантической модели.
- Сметная стоимость строительства, принятая по Главе 2 сводных сметных расчетов по результатам разработки проектно-сметной документации (данные с сайта государственных закупок).cx
Таблица 4.
Результаты верификации алгоритма на выборке из 5 объектов ФАПов
|
Объект ФАП № |
Площадь по ТЗ (м²) |
Площадь по ПСД (м²) |
Расхождение площадей (%) |
Диапазон стоимости (ИИ), тыс. руб. |
Сметная стоимость (ПСД), тыс. руб. |
Отклонение стоимости (%) |
|---|---|---|---|---|---|---|
|
1 |
122,7 |
117,9 |
4,1% |
2 847 – 3 112 |
2 951 |
~3,5% |
|
2 |
94,2 |
98,5 |
4,6% |
2 412 – 2 587 |
2 524 |
~1,5% |
|
3 |
152,1 |
147,3 |
3,3% |
3 215 – 3 498 |
3 352 |
~1,3% |
|
4 |
108,5 |
113,2 |
4,3% |
2 721 – 2 899 |
2 813 |
~0,3% |
|
5 |
89,7 |
86,4 |
3,8% |
2 104 – 2 297 |
2 251 |
~2,2% |
2.3. Верификация полученных результатов
В результате верификации полученных результатов можно сделать вывод о том, что среднее расхождение между данными ТЗ и ПСД — 4,0%, что является приемлемым отклонением на стадии предпроектного анализа, по сравнению с действующими методиками прогнозирования по объектам-аналогам и укрупненным сметным нормативам (до 15%). Во всех случаях сметная стоимость попала в предсказанный ИИ диапазон.
Получена весьма высокая стабильность работы алгоритма, даже при разбросе площадей до 5% стоимость остаётся в прогнозируемом коридоре.
Выводы
Проведённый анализ современных подходов к цифровизации строительного проектирования демонстрирует, что искусственный интеллект и семантические технологии обладают значительным потенциалом для автоматизации обработки неструктурированных данных, особенно на ранних этапах проектирования. Использование NLP-инструментов, таких как spaCy и BERT, позволяет эффективно извлекать ключевые параметры из текстовых технических заданий, обеспечивая переход от свободной формы описания к структурированному представлению информации.
Создание онтологий на основе нормативных баз данных (включая ГЭСН) в формате RDF открывает возможность для семантической интеграции проектных решений с нормативной базой, повышая точность и согласованность сметных расчетов. Применение rule-based и машинно-обучающихся методов сопоставления строительных конструкций с соответствующими сметными нормами способствует формированию более адаптивной и интеллектуальной системы ценообразования.
[1] Согласно ISO 19650-1:2018 Organization and digitization of information about buildings and civil engineering works, including BIM — Part 1: Concepts and principles.
[2] Приказ Минстроя России от 1 марта 2018 года N 125/пр. Об утверждении типовой формы задания на проектирование объекта капитального строительства и требований к его подготовке.
[3] Перечень национальных стандартов и сводов правил (частей таких стандартов и сводов правил), в результате применения которых на обязательной основе обеспечивается соблюдение требований Федерального закона "Технический регламент о безопасности зданий и сооружений". Утвержден постановлением Правительства Российской Федерации от 28 мая 2021 г. N 815.
1. Azhar S. Building Information Modeling (BIM): Trends, Benefits, Risks, and Challenges for the AEC Industry // Leadership and Management in Engineering. 2011. 11(3), 241–252. DOI:https://doi.org/10.1061/(ASCE)LM.1943-5630.0000127.
2. Гудзь С. В. Проблемы интеграции сметного ценообразования в технологии информационного моделирования // Столыпинский вестник. – 2023. – №4. EDN: https://elibrary.ru/WAZRYY
3. Герасимова А. Р. Развитие сметного дела в рамках BIM-технологии в сфере строительства Российской Федерации // Молодой ученый. 2023. №23 (470). С. 108-111. EDN: https://elibrary.ru/CJNGJI
4. Gozde O. Interoperability in building information modeling for AECO/FM industry. // Automation in Construction. 2020. 113.https://doi.org/10.1016/j.autcon.2020.103122.
5. Shehab A., Abdelalim A. Utilization BIM for integrating cost estimation and cost control in construction projects // International Journal of Management and Commerce Innovations. 2023. DOI:https://doi.org/10.5281/zenodo.7923308.
6. Tyurin I. Methods of computer modeling of cost models for buildings // IOP Conference Series: Materials Science and Engineering. 2020. 062031. 869. DOI: https://doi.org/10.1088/1757-899X/869/6/062031
7. Tyurin I. Automation identification of construction work and structural elements in BIM development // IOP Conference Series: Materials Science and Engineering. 2020. 042010. 913. DOI: https://doi.org/10.1088/1757-899X/913/4/042010
8. Tyurin I. A., Ginzburg A. V. Increasing the economic efficiency of design and construction solutions due to the automated identification of construction works and structural elements of information models // IOP Conference Series: Materials Science and Engineering. 2021. 012076. 1083. DOI: https://doi.org/10.1088/1757-899X/1083/1/012076
